
##前言:
本週進入第二個禮拜,開始有一些分散式系統的備份與替換的問題還有論文. 加油吧!!
MIT 6.824 分散式系統 系列文章
- [MOOCS][Golang]MIT6_824 Distributed Systems Week2(Lec2/Lab2A)
- [MOOCS][Golang]MIT6_824 Distributed Systems Week2(Lec2/Lab2A)
- [MOOCS][Golang]MIT6_824 Distributed Systems Week2(Lec2/Lab2B)
- [MOOCS][Golang]MIT6_824 Distributed Systems Week3- About Paxos Algorithm
- [MOOCS][Golang]MIT6_824 Distributed Systems Week4- 關於Consensus協定 Raft 學習(一): 簡介,資料格式與領導者選舉
##第二週課程:
##關於筆記 Primary/Backup Replication (Remus)
盡量用理解後的中文紀錄,原始筆記在這裡:
- 關於容錯(Fault Tolerance):
- 希望能繼續服務儘管有問題發生. 特性如下:
- 可見性: 即使有問題發生,也希望服務能夠繼續.
- 正確性: 希望發生問題的時候,服務也跟單機一樣(無錯誤時)正確.
- 核心想法: 備份,透過兩個或是以上的備份伺服器來預防任何的問題產生.
- 重要問題:
- 備份機的狀態?
- 工作機的狀態如何轉移?
- 何時要切開與備份機的連接?
- 異常發生在切開之後?
- 如何修復與重新連接備份機?
- 重要問題:
- 兩個關於備份機的重要動作:
- State Transfer (狀態轉移)
- Replicated State Machine: (備份狀態機)
- 希望能繼續服務儘管有問題發生. 特性如下:
##論文 Remus: High Availability via Asynchronous Virtual Machine Replication
這裏有網頁版本
Remus 的系統特色:
- 整個系統備份
- 對於Application與Client而言是透明的.
- 當運行成功的時候,備份與切換機器就運作順暢
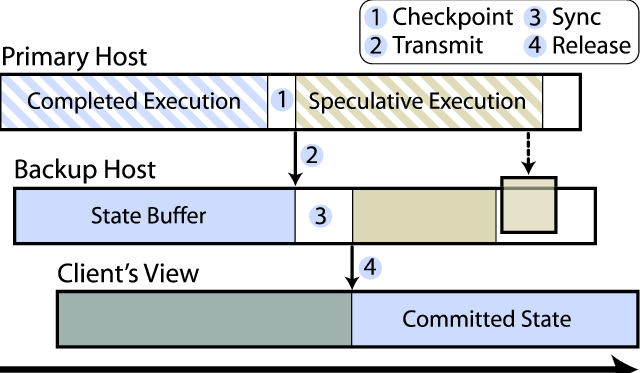
圖片元素解釋:
- Primary: 具有資料,會執行OS與App,並且負責跟Client溝通.
- Backup: 只有資料,但是不執行OS與App.只有跑一些Remus的code
流程簡介:
- (1) Primary 跑完 Completed Execution (E1),並且先不回傳E1結果回client.
- (2) Primary把結果備份到Backup (背景執行)
- (3) Backup同步所有目前資料跟Primary一樣.
- (4) Primary 執行Speculative Exection (E2),並且先不回傳給client
- (5) Backup 複製所有結果
- (6) Primary放出E1結果
- (7) Backup 把結果存入RAM/Disk.
Remus 特性與檢討:
Remus系統的估計
- 速度為單機系統的1/2~1/4
- Check point時間過久
- 為了要能夠與client溝通,保留結果的時間不能太久
缺點
- 速度不快:
- 由於每個Exection都必須等待Backup 複製好相關資料。
- Check point 至少等花上100ms
如何改善:
- 減少主機儲存資料
- 減少狀態的資料量,或是優化資料格式
- 試著傳送指令而非狀態
##關於Lab2 Part A:ViewService
這一篇有點困難,所以稍微做點筆記:
###題目解釋: 主要要implement 一個具有faul-toerant的key/values services- Viewservice.這個Service有以下的幾個功能:
- 監控 Primary (指的是原始service) 與 Backup(備份用的Service)是否是正常工作.
- 正常而言,如果Primary壞了,會自動地把Backup promoted成 primary.此時如果有空的server就會拉近來變成新的Backup.
- 當新的Primary與Backup上線後,Primary還有一個工作:
- 備份所有資料庫給Backup
- 所有的command set傳給Backup去確保Primary與Backup state machine是一致的.
關於ViewService的Primary/Backup轉移範例如下:
- Primary (Server 1: S1) 發生問題,而Client 送給 S1 一個需求OP1.
- Primary 轉發OP1 給 Backup(Server 2: S2), 這個動作是之前提到為了同步的關係.S1會把每個收到的指令透過forward轉給S2
- 但是由於S2已經被promote成新的Primary.而這時尚未有新的Backup上線.
- S2 回傳一個Error 給 S1 並且Forward給 Client 說已經沒有Backup Server.
- ViewService會把S2設定成新的Primary target address 並且把新的指令都直接轉給 S2.
###開始解答:
打開viewsource這個資料夾,主要有幾個需要注意的:
server.go:主要code的部分.裡面主要有以下幾個部分需要思考:Ping(): 主要負責的是接受Server的Ping,在其中包含著Server本身的資訊與現在資料的View numberGet(): 取得資料Tick(): 這個也就是所謂的定期Heartbeat 也可以說經過一段時間會自動啟動的timer,如果有任何Server掛掉,必須要在這裡處理.
test_test.go:本次作業的測試程式,需要好好思考其中代表的涵意
####進階與Server有關的邏輯與含意
這邊可以參考它提供的圖片:
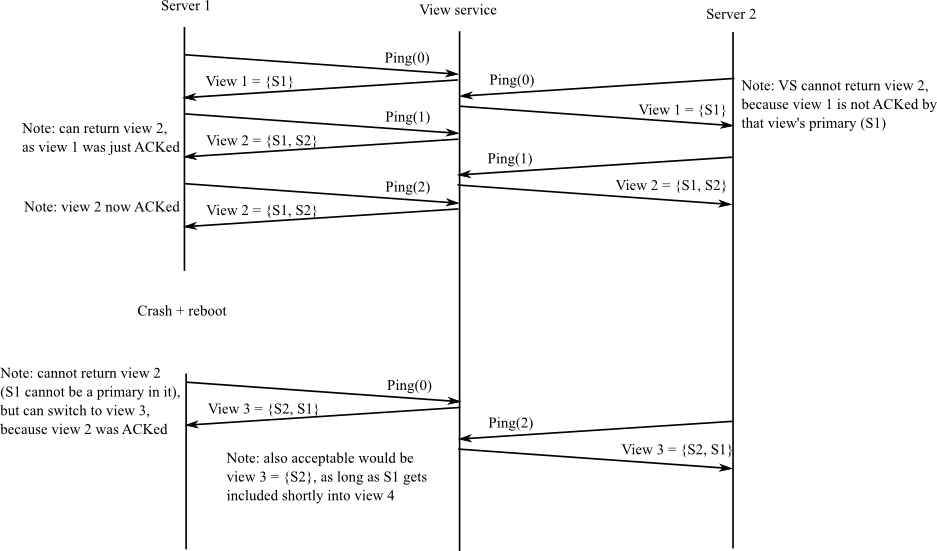
在這裡也整理一下幾個需要注意的地方:
- 其中
Viewnum代表的涵意:Viewnum代表Server所直接到的一個state或是第幾個View.他應該是一個會慢慢增加的部分.
- 如何判定Server已經掛了:
Viewnum忽然變成0,如果原先的viewnum已經>0,但是在某些狀況下忽然收到viewnum=0.那麼就是代表Server已經掛掉又重新執行.- 每一次Server的
Ping,需要紀錄當時的時間.然後在tick裡面去檢查DeadPings * PingInterval來確認Server是否掛了,但是某些狀況下可以當作是Server 繼續活著 (請看Ack).
- 當Server掛掉的處理流程:
- 如果是Primary掛掉,檢查是否有Backup.如果Backup已經正常在運作了,就把他切換成Primary. 並且把第三台主機當作Backup.
- 如果是Backup掛掉,一樣會檢查是否有第三台主機,並且把它掛起來.
- 回應(acknowledgement):
- 在這裏一次的
Get()與Ping()被視為是一次的回應.並且注意Ping()的viewnum必須要大於0,才能表示他已經開始運作. - 如果Primary主機有做
Get(),但是卻沒有回應Ping(),在這次的處理必須等待而不能直接把主機關閉.(倒數第二個測試)
- 在這裏一次的
- 伺服器初始化(Initialization):
- 身為Backup主機,我們必須要確認Backup已經上線了(Online),唯一的方式就是確保他已經有
Ping()一個數值超過0的viewnum - 如果Backup沒有初始化,是不能夠當作Primary的(最後的測試)
- 身為Backup主機,我們必須要確認Backup已經上線了(Online),唯一的方式就是確保他已經有
####心得與改進:
透過這些test case來開始這部分的作業,其實相當的有趣.一開始最令人困擾的是三個function不知道要拿來做什麼.其實題目不算是相當的清楚來解釋每一個步驟. 只能不斷地透過go test一步步來瞭解到底每一個流程,每一個原則會是什麼.這邊算是比較有趣也比較好玩的部分.
此外,由於流程裡要代表的狀態相當的多.一下子要確認主機是否有ack,一下又要確認有沒有init.簡單的做法可以透過許多個flag來代表個別的狀態. 當然,也可以使用狀態機(state machine)的方式方式來開發這次的作業. 只是要有可能會打掉重練的打算.
幾種重練的做法:
- Go Closure: 詳細實作可以參照c9的c6::lexer
寫完作業後,對於論文Remus: High Availability via Asynchronous Virtual Machine Replication也比較容易了解了.
##參考文章:
-
Remus: High Availability via Asynchronous Virtual Machine Replication
- 上海交大報告: 虚拟机容错
- 有些簡單介紹,對於Remus的備份機制有初步了解.
- 基于 Remus 的双机热备份优化机制研究
- 針對備份機制的優化研究,可以拿來參考.

