
September 22nd, 2016



課程鏈結: 這裡
學習鏈結:
前提:
到了新公司,其實也是躲不開繼續學習的宿命.不過可能是因為圍繞的人還是一樣 XD 這個課程是同事推薦,當然要來好好看看.
目前已經到了 Week1 與 Week2. 也順便大概跟大家介紹一下整個課程與內容,希望能讓更多人喜歡這堂課.
課程內容:
這裡先簡單的介紹整系列的課程內容,希望能讓大家了解這個課程想做什麼.
這整堂課主要是圍繞著 Cloud Computing 經常會使用到的技術與相關的概念. 整堂課其實只有一個程式語言作業:
使用 C++ 寫 Gossip Protocol
雖然課程裡面程式語言的作業不多,但是整體上的內容還算不少. 除了有談到一些雲端技術的基本概念:
- Map Reduce
- Multicasting and Gossip Protocol
- P2P Protocol and System
- K/V DB, NOSQL, and Cassandra (畢竟都談了 Gossip)
- Consensus Algorithm - Paxos, FLP Proof
其實課程內容很有料,也可以學到很多的東西.
Week1 Orientation, Introduction to Clouds, MapReduce
講解不少的 Data Center 與分散式系統的基本概念,簡單地列一下幾個重點:
- Data Center PUE (Power usage effectiveness )
- 通常這個數字一定會大於 1 (業界大概是 1.4~1.5)

- 分散系統中有談到 Map Reduce 要如何運作:
- YARN 是透過 RM (Resource Manager ) 來控制全部的系統工作分配.
- MapReduce
- Map 分配工作
- Reduce 根據 key 將重複的結果合併起來.
Week2: Gossip, Membership, and Grids
這一個章節主要開始介紹 Gossip 的一些原理,稍微節錄如下:
Multiple-Cast:
- 單節點向所有節點廣播
- 透過 ACK (Acknowlegement) 與 NACK (negative acknowledgements) 來表示有收到或是沒有收到.
- 時間複雜度: \(O(n)\)
Gossip
- Gossip broacast (UDP)
- There are two mode about broadcast:
- Push
- 時間複雜度 \(O(log_n)\)
- Pull
- 時間複雜度 \(O( log(log_n) )\)
- Push
- Fault Torrent:
- Packet Lost: 50% 封包遺失,依舊可以正常運作.
- Node Failure: 可以有一半左右的節點失效,還是可以正常運作.
- Gossip-Style Failure Detection (Heartbit)
- 每個節點會針對 member list (各自維護一份) 來做定期的 heartbit. (該時間為 \(T_gossip\) )
- 每次收到之後,local member list 會更新並且把最新收到的時間更新進去.
- 只要時間超過了 \(T_fail\) 之後,就會被當成是無效節點.並且在 \(T_cleanup\) 之後來清理掉.
- 為何需要兩個時間? 有一種可能是,節點被認為失效了.但是過了 \(T_fail\) 忽然又活起來的話,就可以被加入回去.
- 結論: 如果 \(T_fail\) 與 \(T_cleanup\) 越大,越容易 false positive .但是可以節省流量.
Probabilistic Faulure Detection (SWIM Gossip)
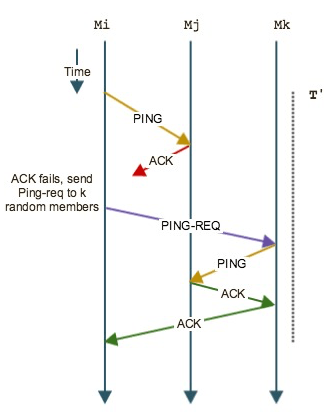
當 \(M_i\) 與 \(M_j\) 無法直接連接的時候,節點 \(M_i\) 會隨機發送到第 k 個節點 ( \(M_k\) ) 來做另一個方面的確認.
如此一來,如果 \(M_k\) 會嘗試去 ping \(M_j\) ,如果取得正常的反應.就代表節點 \(M_j\) 依舊是活著,可能只是 toponology \(M_i -> M_j\) 有問題發生.
當有 n 個節點,要能夠透過傳遞來知道一個節點壞掉需要透過 \(O(log(N))\) 的時間.
Dissemination and suspicion
- 傳播(Dissemination) Member List 的途徑:
- Multicast (Machine-IP) 比較不可靠
- TCP/UDP 比較可靠 (不過 UDP 也沒有 handshake)
- 也可以透過 Piggybacked 就是 ping 夾帶 member list 方式來傳遞 member list
作業相關學習
TBC