
October 6th, 2016


![]()

前言
話說強者我同事 Simon Su 是 GCPUG 是主辦者. 當然還是得特地跟老婆請假來彭場一下,加上本週有不少資料科學相關的講題.
1. Apache Beam in Big Data Pipeline by Randy Huang - Data Architect at VMFive
Why use beam?
-
If you want to decompose your task into pipeline. You can focus on algorithm.
-
It could run on Flink, Storm and Spark. So you can write code once run anywhere.
Q&A
- What is the pain point if such application has so much runner? (spark, flink, storm)
- Ans:
- No, pain point until now. Sometime CEP for Flink but might not able to use in Beam.
- Beam is follow Flink related API closely.
- Ans:
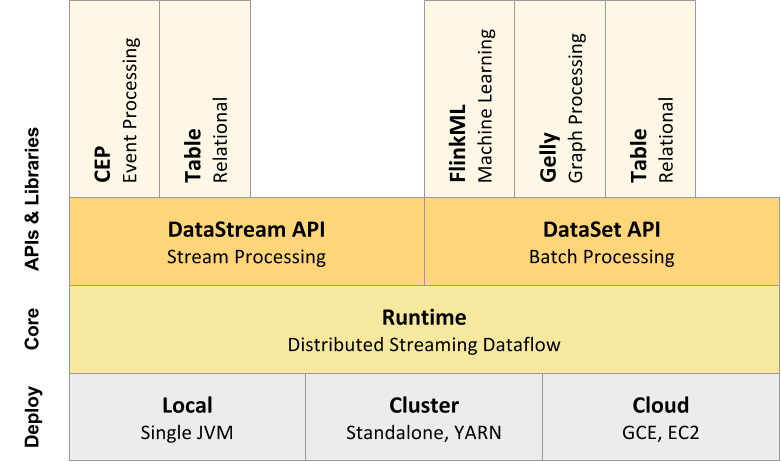
Related Link:
2.Kubernetes 使用心得分享 by Gene Liu / LIVEhouse.in
- Self healing in second.
- Master will use 0.4 CPU in etcd.
Q&A
- Is any way to assign random port in Kubernetes Cluster if we want to run random replica?
- Ans:
- Use node pool
- Ans:
- Why use kubernetes?
- Ans:
- It is deep link with Google Cloud.
- Easy to integrate with Google Cloud Service.
- Ans:
3. 認識Dataflow by Simon Su/Cloud Architect at LinkerNetworks
The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing - 中文論文讀後心得
可惜最後沒聽完…..