

前情提要
在工作和生活中,我們經常需要處理大量的文件:會議記錄、技術文件、合約、研究報告等等。每次要找特定資訊時,都得翻開文件一頁一頁找,既費時又容易遺漏重點。
最近 Google 推出了 Gemini File Search API,讓 AI 可以直接分析上傳的文件並回答問題。我想到,如果能結合 LINE Bot,讓大家透過最常用的通訊軟體就能「問」文件問題,那不是很方便嗎?
想像一下這些場景:
- 📄 會議記錄:「這次會議的主要決議是什麼?」
- 📊 技術文件:「這個 API 的參數有哪些?」
- 🖼️ 圖片內容:「這張圖片裡有什麼?」
- 📑 研究報告:「這份報告的結論是什麼?」
於是我決定動手打造這個「智能文件助手 LINE Bot」,讓 AI 成為你的私人文件分析師!
專案程式碼
https://github.com/kkdai/linebot-gemini-file-search
(透過這個程式碼,可以快速部署到 GCP Cloud Run,享受無伺服器的便利)
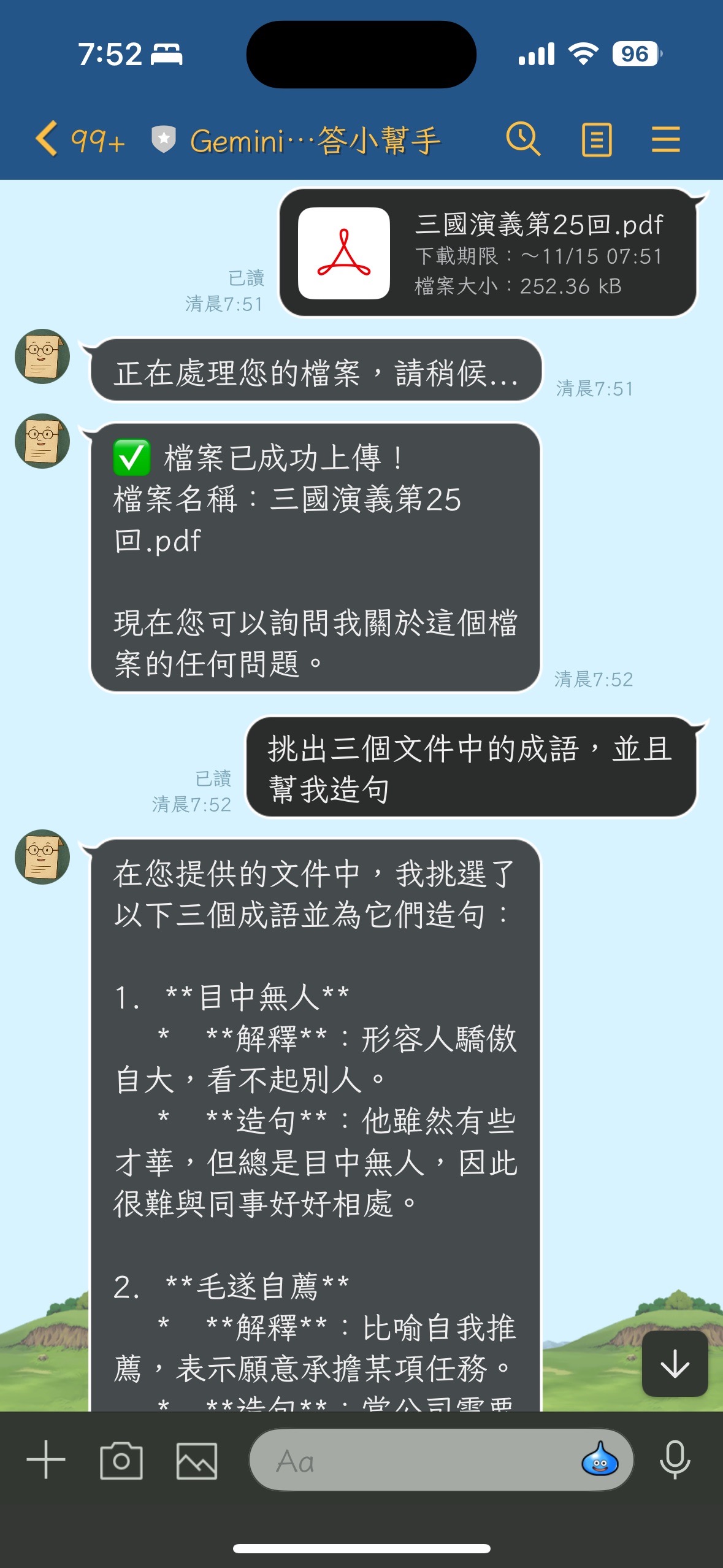
📚 關於 Gemini File Search 基本介紹
Gemini File Search 是 Google DeepMind 於 2025 年 11 月 6 日推出的全新工具,直接內建在 Gemini API 之中。這個工具是一套全託管的 RAG(檢索增強生成,Retrieval-Augmented Generation)系統,目標是讓開發者能更簡單、有效率地將自己的資料與 Gemini 模型結合,產生更精確、相關且可驗證的 AI 回應。
主要特色
- 簡化開發流程 File Search 免去自行搭建 RAG 管線的麻煩,開發者只需專注於應用程式本身。檔案儲存、分段(chunking)、嵌入(embedding)及檢索等繁瑣細節都自動處理。
- 強大的向量搜尋 採用最新的 Gemini Embedding 模型,可理解使用者查詢的語意與上下文,找出最相關的資訊,即使關鍵字不同也能命中答案。
- 自動引用來源 AI 回應會自動附上出處,明確標示答案引用自哪一份文件、哪一段內容,方便核對與驗證。
- 廣泛格式支援 支援 PDF、DOCX、TXT、JSON 及多種程式語言檔案等主流格式,方便建立多元知識庫。
- 輕鬆整合
可直接在
generateContentAPI 中使用,且有完善的 Python SDK,開發者能快速上手。
📚 專案功能介紹
核心功能
- 📤 多格式檔案上傳
- 支援文件檔案:PDF、Word (DOCX)、純文字 (TXT) 等
- 支援圖片檔案:JPG、PNG 等(利用 Gemini Image Understanding 圖片內容)
- 自動處理中文檔名,避免編碼問題
- 即時回饋上傳狀態
- 🤖 AI 智能問答
- 基於 Google Gemini 2.5 Flash 模型
- 從上傳的文件中搜尋相關內容並回答
- 支援繁體中文、英文等多語言
- 理解上下文,提供精準回答
- 👥 多對話隔離
- 1對1聊天:每個人有獨立的文件庫(完全隔離)
- 群組聊天:群組成員共享文件庫(協作查詢)
- 自動識別對話類型,無需手動設定
- File Search Store 自動建立和管理
- 📁 檔案管理功能
- Quick Reply 快速操作:上傳成功後提供快捷按鈕
- 明確檔案指定:Quick Reply 自動帶入檔案名稱
- 🔄 智能錯誤處理
- 檔案上傳失敗自動重試
- 沒有文件時引導使用者上傳
- 詳細的錯誤日誌記錄
💻 核心功能實作
1. File Search Store 的自動管理
這是整個系統的核心,負責管理每個使用者或群組的文件庫。
Store 命名策略
根據對話類型自動生成唯一的 store 名稱:
def get_store_name(event: MessageEvent) -> str:
"""
Get the file search store name based on the message source.
Returns user_id for 1-on-1 chat, group_id for group chat.
"""
if event.source.type == "user":
return f"user_{event.source.user_id}"
elif event.source.type == "group":
return f"group_{event.source.group_id}"
elif event.source.type == "room":
return f"room_{event.source.room_id}"
else:
return f"unknown_{event.source.user_id}"
Store 存在性檢查與建立
關鍵的設計是:File Search Store 的 name 是由 API 自動生成的(例如 fileSearchStores/abc123),我們只能設定 display_name。因此需要透過 list() 和 display_name 來查找:
async def ensure_file_search_store_exists(store_name: str) -> tuple[bool, str]:
"""
Ensure file search store exists, create if not.
Returns (success, actual_store_name).
"""
try:
# List all stores and check if one with our display_name exists
stores = client.file_search_stores.list()
for store in stores:
if hasattr(store, 'display_name') and store.display_name == store_name:
print(f"File search store '{store_name}' already exists: {store.name}")
return True, store.name
# Store doesn't exist, create it
print(f"Creating file search store with display_name '{store_name}'...")
store = client.file_search_stores.create(
config={'display_name': store_name}
)
print(f"File search store created: {store.name} (display_name: {store_name})")
return True, store.name
except Exception as e:
print(f"Error ensuring file search store exists: {e}")
return False, ""
Cache 機制優化
為了避免每次都要 list 所有 stores,我們加入了快取機制:
# Cache to store display_name -> actual_name mapping
store_name_cache = {}
# 在上傳時使用 cache
if store_name in store_name_cache:
actual_store_name = store_name_cache[store_name]
else:
success, actual_store_name = await ensure_file_search_store_exists(store_name)
store_name_cache[store_name] = actual_store_name
2. 檔案上傳與狀態管理
完整的檔案上傳流程,包含等待 API 處理完成:
async def upload_to_file_search_store(file_path: Path, store_name: str, display_name: Optional[str] = None) -> bool:
"""
Upload a file to Gemini file search store.
Returns True if successful, False otherwise.
"""
try:
# Check cache first
if store_name in store_name_cache:
actual_store_name = store_name_cache[store_name]
else:
success, actual_store_name = await ensure_file_search_store_exists(store_name)
if not success:
return False
store_name_cache[store_name] = actual_store_name
# Upload to file search store
config_dict = {}
if display_name:
config_dict['display_name'] = display_name
operation = client.file_search_stores.upload_to_file_search_store(
file_search_store_name=actual_store_name,
file=str(file_path),
config=config_dict if config_dict else None
)
# Wait for operation to complete (with timeout)
max_wait = 60 # seconds
elapsed = 0
while not operation.done and elapsed < max_wait:
await asyncio.sleep(2)
operation = client.operations.get(operation)
elapsed += 2
if operation.done:
print(f"File uploaded successfully")
return True
else:
print(f"Upload operation timeout")
return False
except Exception as e:
print(f"Error uploading to file search store: {e}")
return False
3. 智能查詢與 File Search 整合
當使用者提問時,系統會先檢查是否有上傳文件,然後使用 File Search 查詢:
async def query_file_search(query: str, store_name: str) -> str:
"""
Query the file search store using generate_content.
Returns the AI response text.
"""
try:
# Get actual store name from cache or by searching
actual_store_name = None
if store_name in store_name_cache:
actual_store_name = store_name_cache[store_name]
else:
# Try to find the store by display_name
stores = client.file_search_stores.list()
for store in stores:
if hasattr(store, 'display_name') and store.display_name == store_name:
actual_store_name = store.name
store_name_cache[store_name] = actual_store_name
break
if not actual_store_name:
# Store doesn't exist - guide user to upload files
return "📁 您還沒有上傳任何檔案。\n\n請先傳送文件檔案(PDF、DOCX、TXT 等)或圖片給我,上傳完成後就可以開始提問了!"
# Create FileSearch tool with actual store name
tool = types.Tool(
file_search=types.FileSearch(
file_search_store_names=[actual_store_name]
)
)
# Generate content with file search
response = client.models.generate_content(
model=MODEL_NAME,
contents=query,
config=types.GenerateContentConfig(
tools=[tool],
temperature=0.7,
)
)
if response.text:
return response.text
else:
return "抱歉,我無法從文件中找到相關資訊。"
except Exception as e:
print(f"Error querying file search: {e}")
return f"查詢時發生錯誤:{str(e)}"
4. 引用來源(Citations)功能
Gemini File Search API 的一大特色就是會自動提供引用來源,讓使用者可以驗證 AI 回答的準確性。我們實作了完整的引用功能:
提取 Grounding Metadata
當 AI 回答問題時,會在 grounding_metadata 中包含引用資訊:
async def query_file_search(query: str, store_name: str) -> tuple[str, list]:
"""
Query the file search store using generate_content.
Returns (AI response text, list of citations).
"""
# ... (前面的查詢代碼)
# Extract grounding metadata (citations)
citations = []
try:
if hasattr(response, 'candidates') and response.candidates:
candidate = response.candidates[0]
if hasattr(candidate, 'grounding_metadata') and candidate.grounding_metadata:
grounding_chunks = candidate.grounding_metadata.grounding_chunks
for chunk in grounding_chunks:
if hasattr(chunk, 'web') and chunk.web:
# Web source (網頁來源)
citations.append({
'type': 'web',
'title': getattr(chunk.web, 'title', 'Unknown'),
'uri': getattr(chunk.web, 'uri', ''),
})
elif hasattr(chunk, 'retrieved_context') and chunk.retrieved_context:
# File search source (文件來源)
citations.append({
'type': 'file',
'title': getattr(chunk.retrieved_context, 'title', 'Unknown'),
'text': getattr(chunk.retrieved_context, 'text', '')[:500],
})
print(f"Found {len(citations)} citations")
except Exception as citation_error:
print(f"Error extracting citations: {citation_error}")
return (response.text, citations)
引用快取機制
為了讓使用者可以查看引用詳情,我們實作了引用快取:
# Cache to store citations/grounding metadata for each user/group
# Key: store_name, Value: list of grounding chunks
citations_cache = {}
# 查詢完成後,儲存引用資訊
response_text, citations = await query_file_search(query, store_name)
# Store citations in cache (limit to 3 for Quick Reply)
if citations:
citations_cache[store_name] = citations[:3]
print(f"Stored {len(citations_cache[store_name])} citations for {store_name}")
Quick Reply 引用按鈕
在回答中加入 Quick Reply 按鈕,讓使用者一鍵查看引用詳情:
# Create Quick Reply buttons for citations
quick_reply = None
if citations:
quick_reply_items = []
for i, citation in enumerate(citations[:3], 1): # Limit to 3 citations
quick_reply_items.append(
QuickReplyButton(action=MessageAction(
label=f"📖 引用{i}",
text=f"📖 引用{i}"
))
)
quick_reply = QuickReply(items=quick_reply_items)
# Reply to user with citations
reply_msg = TextSendMessage(text=response_text, quick_reply=quick_reply)
查看引用詳情
當使用者點擊「📖 引用」按鈕時,顯示完整的引用內容:
# Check if user wants to view a citation
if query.startswith("📖 引用"):
# Extract citation number
citation_num = int(query.replace("📖 引用", "").strip())
if store_name in citations_cache and 0 < citation_num <= len(citations_cache[store_name]):
citation = citations_cache[store_name][citation_num - 1]
# Format citation text
if citation['type'] == 'file':
citation_text = f"📖 引用 {citation_num}\n\n"
citation_text += f"📄 文件:{citation['title']}\n\n"
citation_text += f"📝 內容:\n{citation['text']}"
if len(citation.get('text', '')) >= 500:
citation_text += "\n\n... (內容過長,已截斷)"
elif citation['type'] == 'web':
citation_text = f"📖 引用 {citation_num}\n\n"
citation_text += f"🌐 來源:{citation['title']}\n"
citation_text += f"🔗 連結:{citation['uri']}"
reply_msg = TextSendMessage(text=citation_text)
設計要點:
- 兩種引用來源:支援文件引用(file)和網頁引用(web)
- 限制數量:Quick Reply 最多顯示 3 個引用(LINE Bot 限制)
- 內容截斷:文件內容超過 500 字元會自動截斷,避免訊息過長
- 快取機制:每個 store 的引用獨立儲存,避免混淆
- 使用者體驗:一鍵查看引用詳情,無需複製貼上
實際效果:
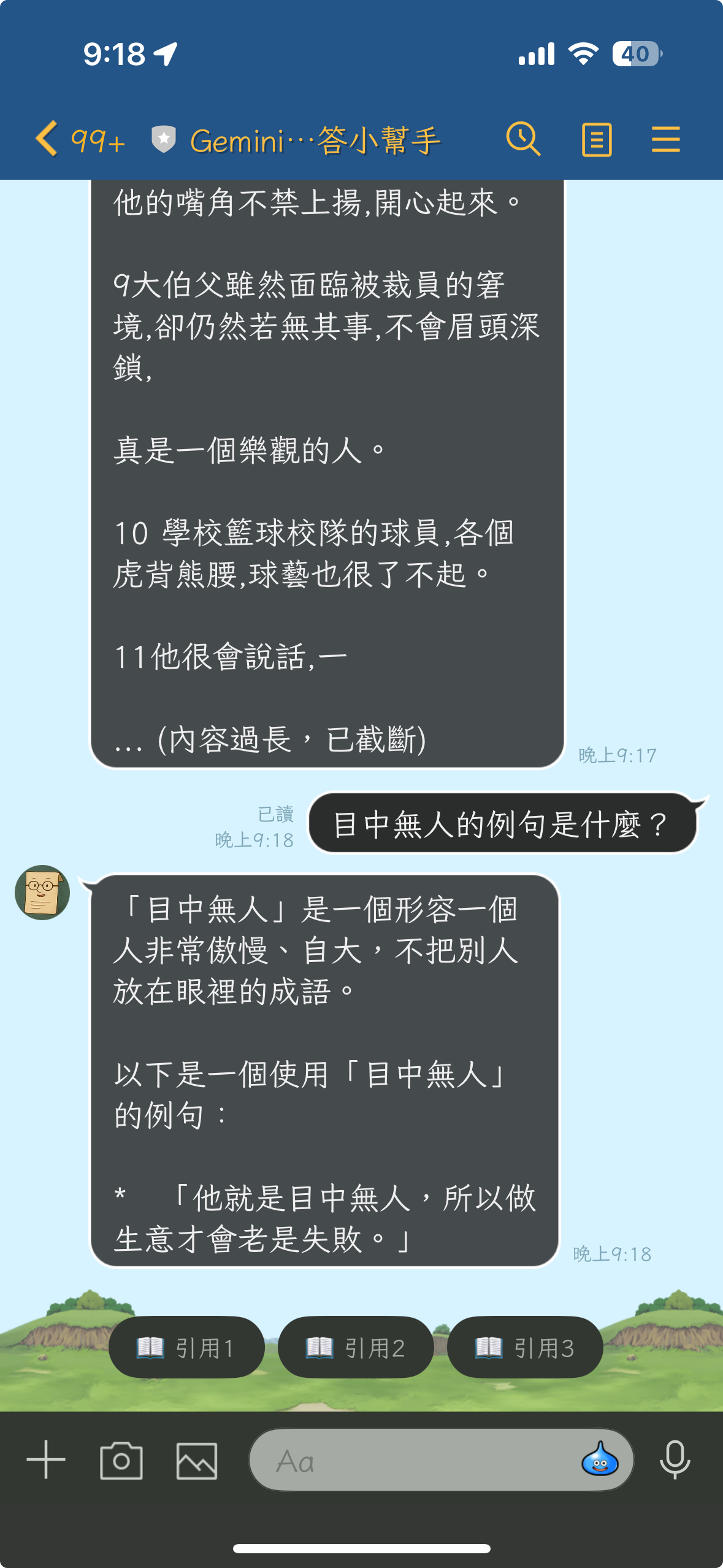
5. Quick Reply 快速操作
當使用者上傳檔案成功後,系統會提供 Quick Reply 按鈕,讓使用者快速執行常見操作:
設計要點:
-
明確檔案名稱:Quick Reply 的文字自動帶入
{file_name},避免多檔案時的混淆 -
一鍵操作:使用者點擊按鈕即可發送完整問題,無需手動輸入
-
常見需求:提供「生成摘要」、「重點整理」等高頻功能
5. 檔案刪除功能
列出文件
使用者可以輸入「列出檔案」等關鍵字來查看已上傳的文件:
def is_list_files_intent(text: str) -> bool:
"""
Check if user wants to list files.
"""
list_keywords = [
'列出檔案', '列出文件', '顯示檔案', '顯示文件',
'查看檔案', '查看文件', '檔案列表', '文件列表',
'有哪些檔案', '有哪些文件', '我的檔案', '我的文件',
'list files', 'show files', 'my files'
]
text_lower = text.lower().strip()
return any(keyword in text_lower for keyword in list_keywords)
刪除文件功能
當使用者點擊刪除按鈕時,透過 Postback 事件處理刪除:
async def delete_document(document_name: str) -> bool:
"""
Delete a document from file search store.
Note: force=True is required to permanently delete documents from File Search Store.
"""
try:
# Try to use SDK method first with force=True
if hasattr(client.file_search_stores, 'documents'):
# Force delete is required for File Search Store documents
client.file_search_stores.documents.delete(
name=document_name,
config={'force': True} # ⚠️ 必須加上 force=True
)
return True
except Exception as sdk_error:
# Fallback to REST API with force parameter
import requests
url = f"https://generativelanguage.googleapis.com/v1beta/{document_name}"
params = {
'key': GOOGLE_API_KEY,
'force': 'true' # ⚠️ 必須加上 force parameter
}
response = requests.delete(url, params=params, timeout=10)
response.raise_for_status()
return True
關鍵重點:
- File Search Store 中的文件是 immutable(不可變)
- 刪除時必須加上
force: True參數,否則會失敗 - 雙重後備機制確保相容性(SDK → REST API)
Postback 事件處理
async def handle_postback(event: PostbackEvent):
"""
Handle postback events (e.g., delete file button clicks).
"""
try:
# Parse postback data
data = event.postback.data
params = dict(param.split('=') for param in data.split('&'))
action = params.get('action')
doc_name = params.get('doc_name')
if action == 'delete_file' and doc_name:
success = await delete_document(doc_name)
if success:
reply_msg = TextSendMessage(
text=f"✅ 檔案已刪除成功!\n\n如需查看剩餘檔案,請輸入「列出檔案」。"
)
else:
reply_msg = TextSendMessage(text="❌ 刪除檔案失敗,請稍後再試。")
await line_bot_api.reply_message(event.reply_token, reply_msg)
except Exception as e:
print(f"Error handling postback: {e}")
🔧 遇到的挑戰與解決方案
1. File Search Store API 的名稱設計
問題:一開始以為可以直接指定 store 的 name,但實際上 create() 不接受 name 參數。
錯誤訊息:
FileSearchStores.create() got an unexpected keyword argument 'name'
原因分析:
- File Search Store 的
name是由 API 自動生成的(格式:fileSearchStores/xxxxx) - 我們只能設定
display_name作為識別 - 需要透過
list()遍歷來查找對應的 store
解決方案:
- 使用
display_name儲存我們定義的名稱(如user_U123456) - 透過
list()找到對應的 store 並取得實際的name - 建立 cache 避免重複查詢
2. 中文檔名的編碼問題
問題:當檔案名稱包含中文時,API 呼叫會失敗。
錯誤訊息:
'ascii' codec can't encode characters in position 19-21: ordinal not in range(128)
問題分析:
# 問題代碼:檔案路徑包含中文
file_path = "uploads/123456_會議記錄.pdf" # ❌ 編碼錯誤
解決方案:
# 解決方案:使用 ASCII 檔名,保留原始名稱供顯示
_, ext = os.path.splitext("會議記錄.pdf")
safe_file_name = f"{message_id}{ext}" # "123456.pdf" ✅
file_path = UPLOAD_DIR / safe_file_name
# 在 config 中保留原始檔名
config = {'display_name': '會議記錄.pdf'} # 用於 AI 回答時的引用
好處:
- 檔案系統操作使用 ASCII 路徑(不會出錯)
- AI 回答時仍然顯示原始中文檔名(使用者友善)
3. Store 不存在時的 404 錯誤
問題:首次上傳檔案時,store 還不存在就嘗試上傳。
錯誤訊息:
404 Not Found. {'message': '', 'status': 'Not Found'}
解決方案: 在上傳前先檢查並建立 store:
# 1. 檢查 cache
if store_name in store_name_cache:
actual_store_name = store_name_cache[store_name]
else:
# 2. 檢查是否存在,不存在則建立
success, actual_store_name = await ensure_file_search_store_exists(store_name)
# 3. 加入 cache
store_name_cache[store_name] = actual_store_name
# 4. 使用實際的 store name 上傳
operation = client.file_search_stores.upload_to_file_search_store(
file_search_store_name=actual_store_name,
file=str(file_path),
config=config_dict
)
4. 非同步檔案處理
問題:上傳檔案是耗時操作,需要等待處理完成。
解決方案:
- 使用
aiofiles進行異步檔案讀寫 - 使用
asyncio.sleep()而非time.sleep() - 實作輪詢機制等待操作完成
# 等待上傳完成
max_wait = 60 # seconds
elapsed = 0
while not operation.done and elapsed < max_wait:
await asyncio.sleep(2) # 異步等待
operation = client.operations.get(operation)
elapsed += 2
5. VertexAI 不支援 File Search API
問題:原本想支援 VertexAI,但發現 File Search API 只支援 Gemini API。
官方說明: 根據 Google AI 文件,File Search 功能目前只支援透過 Gemini API 使用。
解決方案:
- 移除所有 VertexAI 相關程式碼和設定
- 簡化環境變數配置
- 只需要
GOOGLE_API_KEY即可
6. 刪除文件需要 force 參數
問題:實作刪除文件功能時,直接呼叫 delete() API 會失敗。
錯誤訊息:
刪除失敗,或是沒有回應
原因分析: 根據 Google Gemini File Search API 文件(2025年11月6日發布):
- File Search Store 中的文件是 immutable(不可變的)
- 刪除操作必須使用
force: True參數才能永久刪除 - 如果不加
force參數,API 會拒絕刪除請求
解決方案:
- SDK 方式:在 config 中加上
force: Trueclient.file_search_stores.documents.delete( name=document_name, config={'force': True} # ⚠️ 必須加上 ) - REST API 方式:在 query parameters 中加上
force=trueparams = { 'key': GOOGLE_API_KEY, 'force': 'true' # ⚠️ 必須加上 } response = requests.delete(url, params=params)
關鍵學習:
- File Search 的文件一旦建立就是不可變的
- 如果要「更新」文件,必須先刪除(force delete)再重新上傳
- 這與一般的 Files API 行為不同(Files API 的檔案 48 小時後自動刪除)
🎯 總結與未來改進
專案亮點
- 開箱即用的文件助手:無需安裝 APP,透過 LINE 就能使用
- 智能文件分析:結合 Gemini 2.5 Flash 的強大能力
- 中文友善:完整支援中文檔名和查詢
- 隔離機制:每個對話有獨立的文件庫,安全可靠
- 自動化管理:File Search Store 自動建立,使用者無感知
- 引用來源追蹤:自動提取並顯示 AI 回答的引用來源,可驗證答案準確性
- Quick Reply 便利性:上傳後立即提供快捷操作,查詢後可一鍵查看引用
- 多媒體支援:文件查詢 + 圖片分析,一個 Bot 搞定
實戰經驗分享
在開發過程中,我深刻體會到:
1. API 設計的差異
不同雲端服務的 API 設計理念差異很大:
- Google Gemini:name 由系統生成,開發者設定 display_name
- 需要適應:透過 list + 遍歷來查找資源
這提醒我們:閱讀官方文件比猜測 API 行為更重要。
2. 編碼問題無所不在
即使在 2024 年,編碼問題仍然存在:
- 檔案系統可能不支援 Unicode
- API 可能對特殊字元有限制
- 解決方案:分離「儲存用檔名」和「顯示用檔名」
3. 非同步程式設計的重要性
在處理外部 API 時:
- 使用
async/await避免阻塞 - 使用
asyncio.sleep()而非time.sleep() - 適當的 timeout 設定避免無限等待
4. Immutable 資料的處理
File Search Store 的設計哲學:
- 文件一旦上傳就是不可變的(immutable)
- 刪除需要明確的
force: True參數 - 要「更新」文件必須先刪除再上傳
- 這與其他服務(如 Files API)完全不同
這讓我學到:不同服務有不同的資料模型,不能假設行為一致。
未來改進方向
- 效能優化
- 實作更完整的 cache 機制
- 批次處理多檔案上傳
- 壓縮大型檔案
- 減少 API 呼叫次數
- 功能擴展
- ✅
支援檔案刪除功能(已完成) - ✅
支援列出已上傳檔案(已完成) - ✅
整合圖片理解功能(已完成) - ✅
Quick Reply 快速操作(已完成) - ✅
引用來源追蹤(已完成,支援查看引用詳情) - 支援多檔案批次上傳
- 檔案分類和標籤管理
- 檔案內容全文搜尋
- 引用來源跳轉(如果是文件,顯示頁碼或段落位置)
- ✅
- 使用體驗優化
- Rich Menu 設計
- 更友善的錯誤提示
- 上傳進度顯示(長時間處理時)
- 查詢歷史記錄
- 檔案搜尋功能(按檔名或時間)
- 安全性強化
- 檔案大小限制
- 檔案類型驗證
- 使用者配額管理
- 敏感資料過濾
- Store 定期清理機制
關鍵學習
透過這個專案,我學到了:
- Google Gemini File Search 的正確使用方式與 immutable 資料模型
- Grounding Metadata 的提取與引用來源追蹤機制
- FastAPI 在處理 LINE Bot webhook 的高效性
- Python async/await 在 I/O 密集型應用的重要性
- 編碼問題的處理策略(分離儲存名稱與顯示名稱)
- 雲端原生應用的設計模式
- LINE Quick Reply 的情境化應用與使用者體驗提升(檔案摘要 + 引用查看)
- AI 對話 vs 傳統 UI:選擇合適的互動方式
- API 設計差異:不同服務有不同的資料模型和限制
- 雙重後備機制:SDK + REST API 確保穩定性
- 依賴版本管理:使用版本範圍避免衝突,追蹤官方文檔更新
最重要的是:
AI 不只是聊天機器人,更是強大的內容分析工具。File Search API 讓我們能輕鬆打造專業級的文件問答系統。
Quick Reply 是 LINE Bot 的靈魂**。在正確的時機提供正確的快捷操作,可以大幅提升使用者體驗和操作效率。無論是上傳後的「檔案摘要」還是查詢後的「查看引用」,都讓使用者能快速完成任務。
引用來源讓 AI 回答更可信。透過 Grounding Metadata 提取引用資訊,使用者可以驗證 AI 的回答來源,這對於專業文件分析特別重要。結合 Quick Reply 的一鍵查看,讓引用功能真正實用。
依賴管理是持續挑戰。新興框架(如 Google ADK)的 API 變化快,需要持續追蹤官方文檔和 GitHub。使用版本範圍而非固定版本,可以提高相容性,但也要注意 breaking changes。
希望這個經驗分享能幫助到正在探索 AI 應用開發的朋友們!
相關資源
如果你覺得這個專案有幫助,歡迎給個 Star ⭐,或是分享給需要的朋友!
- Python (35) ,
- LINE Bot (10) ,
- GCP (11) ,
- Gemini (24) ,
- FastAPI (1) ,
- Cloud Run (2) ,
- File Search (1)

